This archive contains answers to questions sent to Unidata support through mid-2025. Note that the archive is no longer being updated. We provide the archive for reference; many of the answers presented here remain technically correct, even if somewhat outdated. For the most up-to-date information on the use of NSF Unidata software and data services, please consult the Software Documentation first.
All,
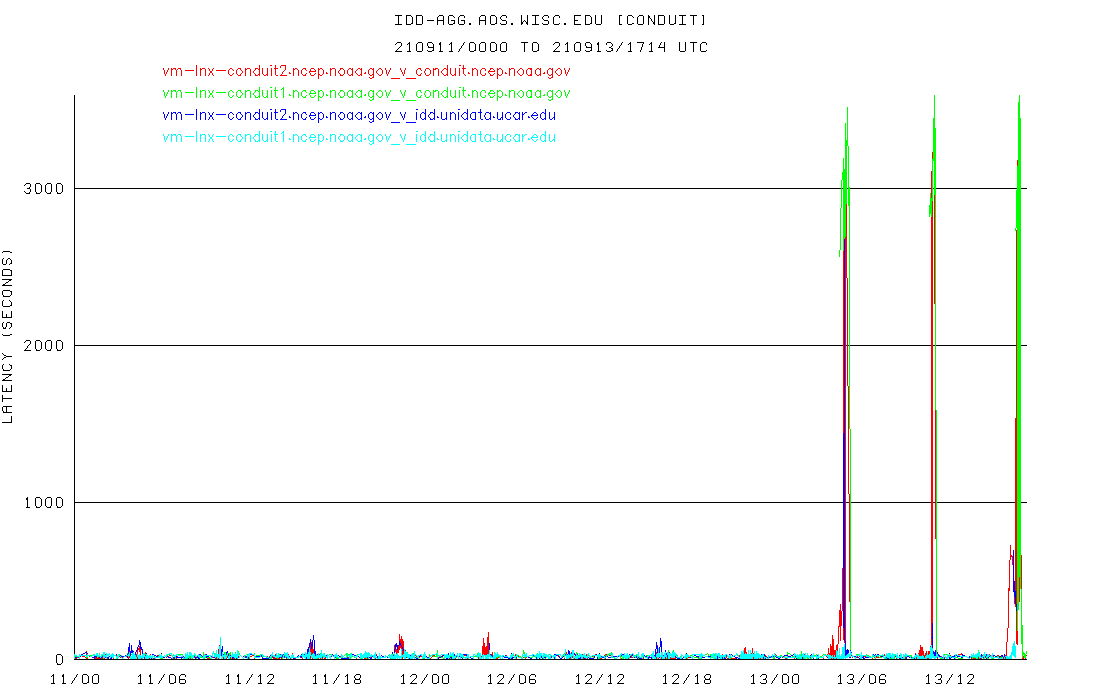
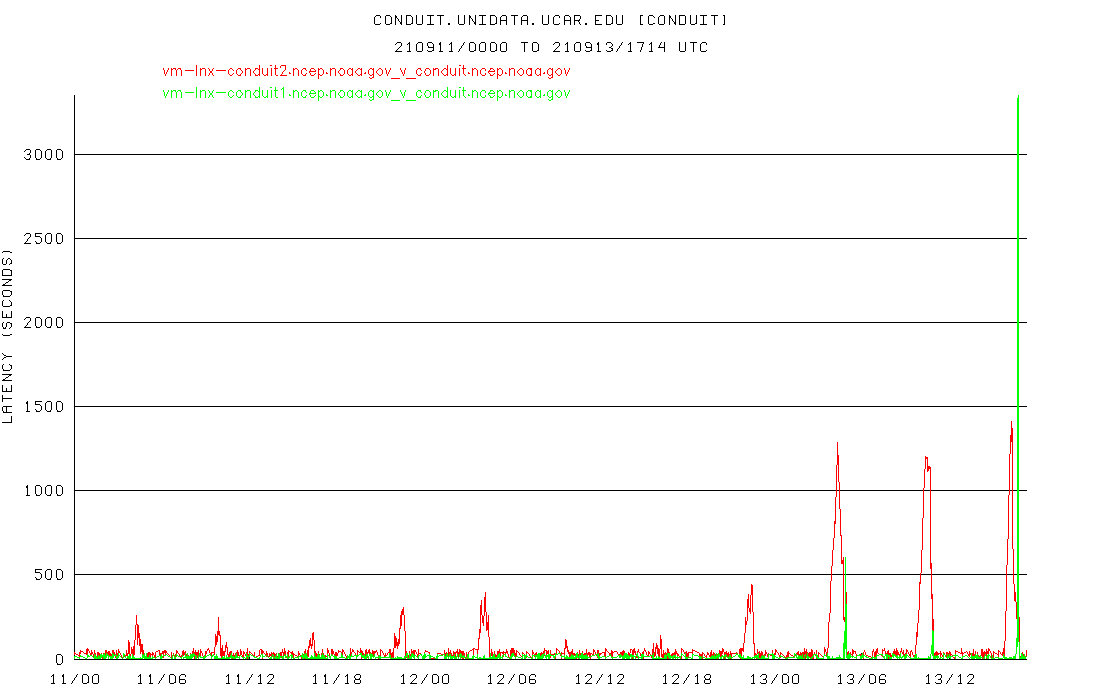
Things were great over most of the weekend, but then took a dive starting with last night's 00 UTC 20210913 run. The lags at Unidata went up as well, so I don't think it's something on our end.
Did something change before last night's 00 UTC run?
Pete
-----
Pete Pokrandt - Systems Programmer
UW-Madison Dept of Atmospheric and Oceanic Sciences
608-262-3086 - address@hidden
From: Jesse Marks - NOAA Affiliate <address@hidden>
Sent: Friday, September 10, 2021 3:02 PM
To: Pete Pokrandt <address@hidden>
Cc: Tyle, Kevin R <address@hidden>; _NWS NCEP NCO Dataflow <address@hidden>; Anne Myckow - NOAA Federal <address@hidden>; address@hidden <address@hidden>; address@hidden <address@hidden>
Subject: Re: [conduit] 20210830: Re: High CONDUIT latencies from vm-lnx-conduit2.ncep.noaa.govHi Pete,
Good to hear and thanks for the quick reply! The work took place between the 06Z and 12Z runs, hence the difference in performance there.
Jesse
On Fri, Sep 10, 2021 at 3:37 PM Pete Pokrandt <address@hidden> wrote:
Hi, Jesse,
I can confirm that today's 12 UTC GFS run seems to have come through completely at UW-Madison and with lower lag after the changes that you made. There were issues with last night's 00 UTC and 06 UTC runs being incomplete - maybe related to the work you were doing? But again, it looks much better now. I will keep an eye on things over the weekend as well, and update you on Monday.
Thank you to all involved in the efforts to get this resolved!!Pete
-----
Pete Pokrandt - Systems Programmer
UW-Madison Dept of Atmospheric and Oceanic Sciences
608-262-3086 - address@hidden
From: Jesse Marks - NOAA Affiliate <address@hidden>
Sent: Friday, September 10, 2021 2:23 PM
To: Pete Pokrandt <address@hidden>
Cc: Tyle, Kevin R <address@hidden>; _NWS NCEP NCO Dataflow <address@hidden>; Anne Myckow - NOAA Federal <address@hidden>; address@hidden <address@hidden>; address@hidden <address@hidden>
Subject: Re: [conduit] 20210830: Re: High CONDUIT latencies from vm-lnx-conduit2.ncep.noaa.govHello All,
We've taken further steps to mitigate this issue today and they appear to have had a positive impact. I did not see heightened latency with today's 12Z GFS run and will monitor the 18Z in a few hours to see if the good behavior persists.
We'll check back in Monday morning to assess how the feed behaved over the weekend and will follow up with you all then. Please let me know if you have any questions/comments or observations that I may have missed.
Thank you,Jesse
On Tue, Sep 7, 2021 at 4:23 PM Pete Pokrandt <address@hidden> wrote:
Happy Tuesday everyone,
Just confirming that whatever is causing the high lag from vm-lnx-conduit2 is still happening. Also, I noticed today that, in addition to forecast hours being incomplete, at least one forecast hour was missing for today's 12 UTC run is completely missing the 78h 1 deg file (gfs.t12z.pgrb2.1p00.f078) - not sure if it was not sent out at all, or if the lag caused us to just miss that file?
Anyways, the issue is still ongoing..
Pete
-----
Pete Pokrandt - Systems Programmer
UW-Madison Dept of Atmospheric and Oceanic Sciences
608-262-3086 - address@hidden
From: Jesse Marks - NOAA Affiliate <address@hidden>
Sent: Friday, September 3, 2021 1:16 PM
To: Pete Pokrandt <address@hidden>
Cc: Tyle, Kevin R <address@hidden>; address@hidden <address@hidden>; _NWS NCEP NCO Dataflow <address@hidden>; Anne Myckow - NOAA Federal <address@hidden>; address@hidden <address@hidden>
Subject: Re: [conduit] 20210830: Re: High CONDUIT latencies from vm-lnx-conduit2.ncep.noaa.govHi All,
We are still actively working this issue. One question - do you know the specific day this problem first appeared?
Thanks,Jesse
On Fri, Sep 3, 2021 at 1:55 PM Pete Pokrandt <address@hidden> wrote:
Kevin,
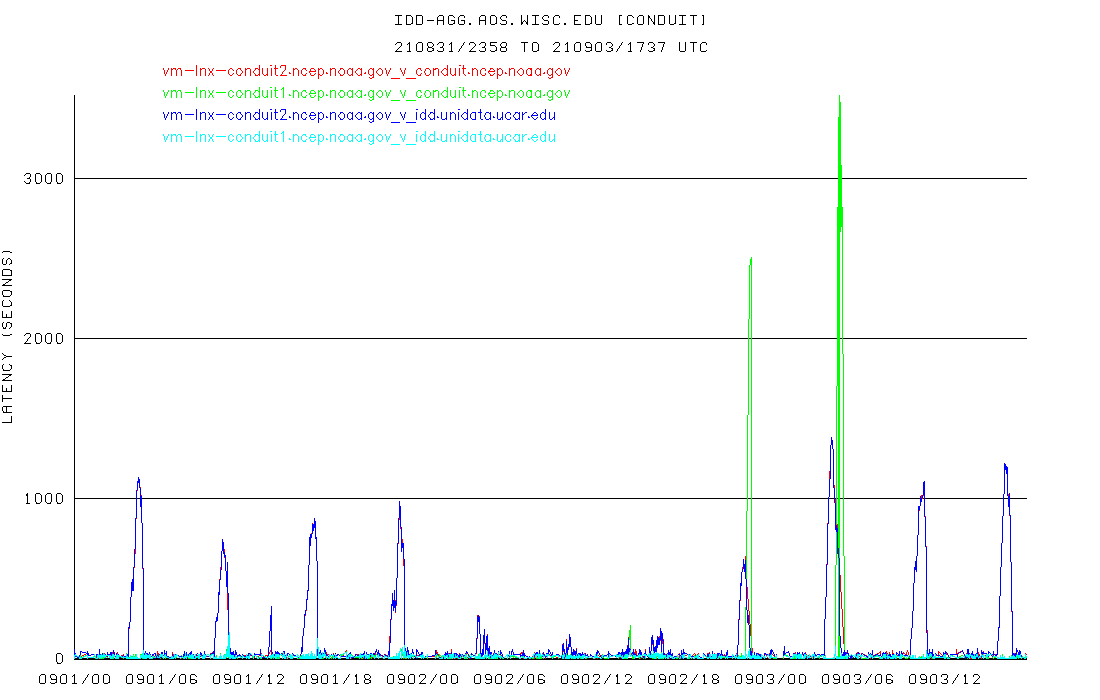
Yes, we are seeing the large lags again, and losing data, I think because it ages out of our ldm product queue before we process it. Unidata folks, are your files also incomplete due to the large lags, or is that specific to us due to a too-small queue? I am looking at the file sizes for the 0.25 deg runs on motherlode, and just looking at the file sizes, it appears Unidata also are missing data. Seems like a complete run should be ~47 Gb, and several are 41, 42, 39Gb..
GFS_Global_0p25deg_20210831_0000.grib2 2021-08-30 23:16 47GGFS_Global_0p25deg_20210831_0600.grib2 2021-08-31 05:14 47GGFS_Global_0p25deg_20210831_1200.grib2 2021-08-31 11:14 47GGFS_Global_0p25deg_20210831_1800.grib2 2021-08-31 17:17 47GGFS_Global_0p25deg_20210901_0000.grib2 2021-08-31 23:16 41GGFS_Global_0p25deg_20210901_0600.grib2 2021-09-01 05:14 47GGFS_Global_0p25deg_20210901_1200.grib2 2021-09-01 11:14 47GGFS_Global_0p25deg_20210901_1800.grib2 2021-09-01 17:17 47GGFS_Global_0p25deg_20210902_0000.grib2 2021-09-01 23:16 47GGFS_Global_0p25deg_20210902_0600.grib2 2021-09-02 05:14 47GGFS_Global_0p25deg_20210902_1200.grib2 2021-09-02 11:15 47GGFS_Global_0p25deg_20210902_1800.grib2 2021-09-02 17:17 47GGFS_Global_0p25deg_20210903_0000.grib2 2021-09-02 23:16 41GGFS_Global_0p25deg_20210903_0600.grib2 2021-09-03 05:14 42GGFS_Global_0p25deg_20210903_1200.grib2 2021-09-03 11:14 39G
If that is the case, that we are both dropping/losing data due to the lags, the maybe problem is that the product queues on the NCEP virtual machines are not large enough to handle the feed, does that seem correct?
My product queue on idd-agg is 78000 Mb (~78 Gb) - but that also handles other data such as the NEXRAD, NEXRAD2, HDS, etc.. however GOES16/17 data does NOT flow through that machine, so it doesn't contribute to the load there.
How big are the product queues on the Unidata CONDUIT ingest machines? Or on the NCEP source machines? Could a possible solution to this be to artificially delay the ingest of the GFS grids a bit to lower the peak amount of data going through? Maybe sleep 20 seconds or a minute or whatever between ingesting each forecast hour? I'd personally rather get a complete data set a bit later than an incomplete data set on time.
Here's the graph of lag from conduit.ncep.noaa.gov to idd-agg.aos.wisc.edu from the past two days. When lags get > 1000 seconds or so, that's the point where we and our downstreams start dropping/losing data..
It would really be helpful to get this resolved, whether it is a fix for whatever's causing the large lags at NCEP, or us acquiring an ingest machine with enough memory to handle a larger product queue (if the issue is us and not the upstream product queues at NCEP), or something other than the CONDUIT data feed to distribute this data, or ?? It has come to the point where we can't rely on this data for plotting maps or doing analysis for classes, initializing local models, etc, because it has become so reliably incomplete, for the GFS runs in particular.
Pete
-----
Pete Pokrandt - Systems Programmer
UW-Madison Dept of Atmospheric and Oceanic Sciences
608-262-3086 - address@hidden
From: Tyle, Kevin R <address@hidden>
Sent: Friday, September 3, 2021 12:06 PM
To: Pete Pokrandt <address@hidden>; Jesse Marks - NOAA Affiliate <address@hidden>; address@hidden <address@hidden>
Cc: _NWS NCEP NCO Dataflow <address@hidden>; Anne Myckow - NOAA Federal <address@hidden>; address@hidden <address@hidden>
Subject: RE: [conduit] 20210830: Re: High CONDUIT latencies from vm-lnx-conduit2.ncep.noaa.govHi all,
After a few good days, we are once again not receiving all GFS forecast hours, starting with today’s 0000 UTC cycle. Pete, do you note the usual pattern of increasing latency from NCEP?
Cheers,
Kevin
_________________________________________________
Kevin Tyle, M.S.; Manager of Departmental Computing
NSF XSEDE Campus Champion
Dept. of Atmospheric & Environmental Sciences
UAlbany ETEC Bldg – Harriman Campus
1220 Washington Avenue, Room 419
Albany, NY 12222
address@hidden | 518-442-4578 | @nywxguy | he/him/his_________________________________________________
From: conduit <address@hidden> On Behalf Of Pete Pokrandt via conduit
Sent: Tuesday, August 31, 2021 12:47 PM
To: Jesse Marks - NOAA Affiliate <address@hidden>; address@hidden
Cc: _NWS NCEP NCO Dataflow <address@hidden>; Anne Myckow - NOAA Federal <address@hidden>; address@hidden; address@hidden
Subject: Re: [conduit] 20210830: Re: High CONDUIT latencies from vm-lnx-conduit2.ncep.noaa.gov
Thanks for the update, Jesse. I can confirm that we are seeing smaller lags originating from conduit2, and since yesterday's 18 UTC run, I don't think we have missed any data here at UW-Madison.
Kevin Tyle, how's your reception been at Albany since the 18 UTC run yesterday?
Pete
-----
Pete Pokrandt - Systems Programmer
UW-Madison Dept of Atmospheric and Oceanic Sciences
608-262-3086 - address@hidden
From: Jesse Marks - NOAA Affiliate <address@hidden>
Sent: Tuesday, August 31, 2021 10:26 AM
To: address@hidden <address@hidden>
Cc: Pete Pokrandt <address@hidden>; Anne Myckow - NOAA Federal <address@hidden>; address@hidden <address@hidden>; address@hidden <address@hidden>; _NWS NCEP NCO Dataflow <address@hidden>
Subject: Re: 20210830: Re: High CONDUIT latencies from vm-lnx-conduit2.ncep.noaa.gov
Thanks for the quick reply, Tom. Looking through our conduit2 logs, we began seeing sends of product from our conduit2 to conduit1 machine after we restarted the LDM server on conduit2 yesterday. It appears latencies improved fairly significantly at that time:
However we still do not see direct sends from conduit2 to external LDMs. Our server team is currently looking into the TCP service issue that appears to be causing this problem.
Thanks,
Jesse
On Mon, Aug 30, 2021 at 7:49 PM Tom Yoksas <address@hidden> wrote:
Hi Jesse,
On 8/30/21 5:16 PM, Jesse Marks - NOAA Affiliate wrote:
> Quick question: how are you computing these latencies?
Latency in the LDM/IDD context is the time difference between when a
product is first put into an LDM queue for redistribution and the time
it is received by a downstream machine. This measure of latency, of
course, requires that the clocks on the originating and receiving
machines be maintained accurately.
re:
> More
> specifically, how do you determine which conduit machine the data is
> coming from?
The machine on which the product is inserted into the LDM queue is
available in the LDM transaction. We provide an website where users
can create graphs of things like feed latencies:
Unidata HomePage
https://www.unidata.ucar.edu
IDD Operational Status
https://rtstats.unidata.ucar.edu/rtstats/
Real-time IDD Statistics -> Statistics by Host
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/siteindex
The variety of measures of feed quality for the Unidata machine that
is REQUESTing the CNODUIT feed from the NCEP cluster can be found in:
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/siteindex?conduit.unidata.ucar.edu
The latencies being reported by the Unidata machine that is being fed
from the NCEP cluster is:
CONDUIT latencies on conduit.conduit.unidata.ucar.edu:
https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/iddstats_nc?CONDUIT+conduit.unidata.ucar.edu
As you can see, the traces are color color coded, and the label at the
top identifies the source machines for products.
re:
> The reason I ask is because I am not seeing any sends of
> product from conduit2 in the last several days of logs both to our local
> conduit1 machine and to any distant end users.
Hmm... we are.
re:
> Also, we have isolated what is likely the issue and will have our team
> take a closer look in the morning. I'm hopeful they'll be able to
> resolve this soon.
Excellent! We are hopeful that the source of the high latencies will
be identified and fixed.
Cheers,
Tom
> On Mon, Aug 30, 2021 at 5:24 PM Anne Myckow - NOAA Federal
> <address@hidden <mailto:address@hidden>> wrote:
>
> Pete,
>
> Random aside, can you please update your doco to say that
> Dataflow's email list is now address@hidden
> <mailto:address@hidden> ? I'm CC'ing it here. That other
> email address is going to get turned off within the next year.
>
> Thanks,
> Anne
>
> On Wed, Aug 18, 2021 at 4:02 PM Pete Pokrandt <address@hidden
> <mailto:address@hidden>> wrote:
>
> Dear Anne, Dustin and all,
>
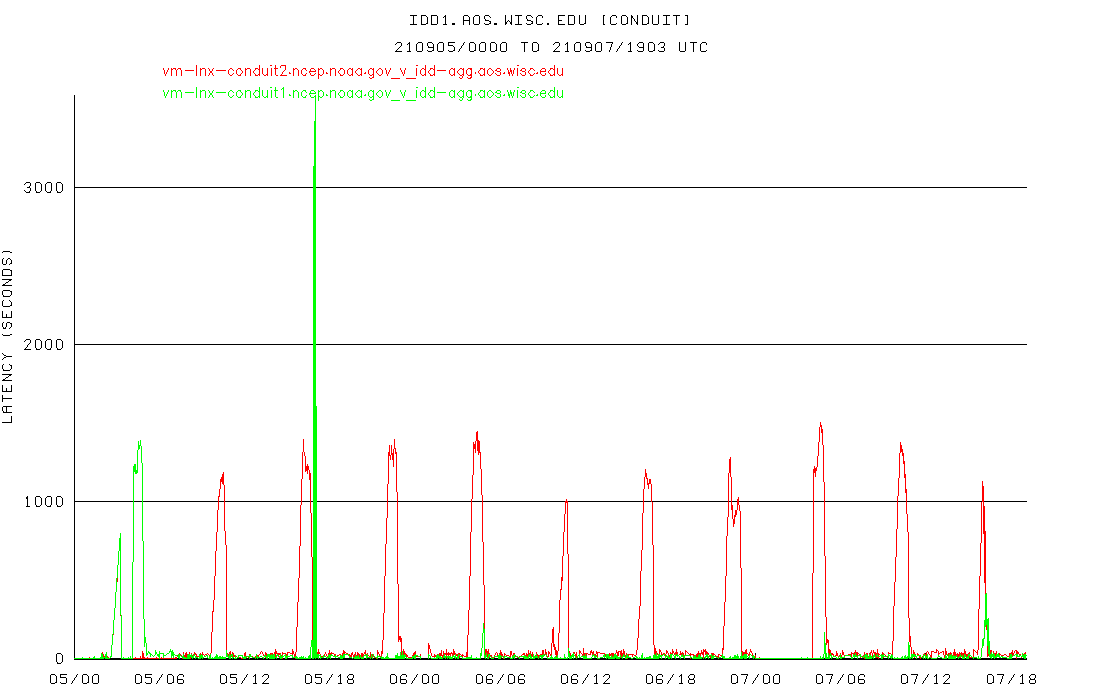
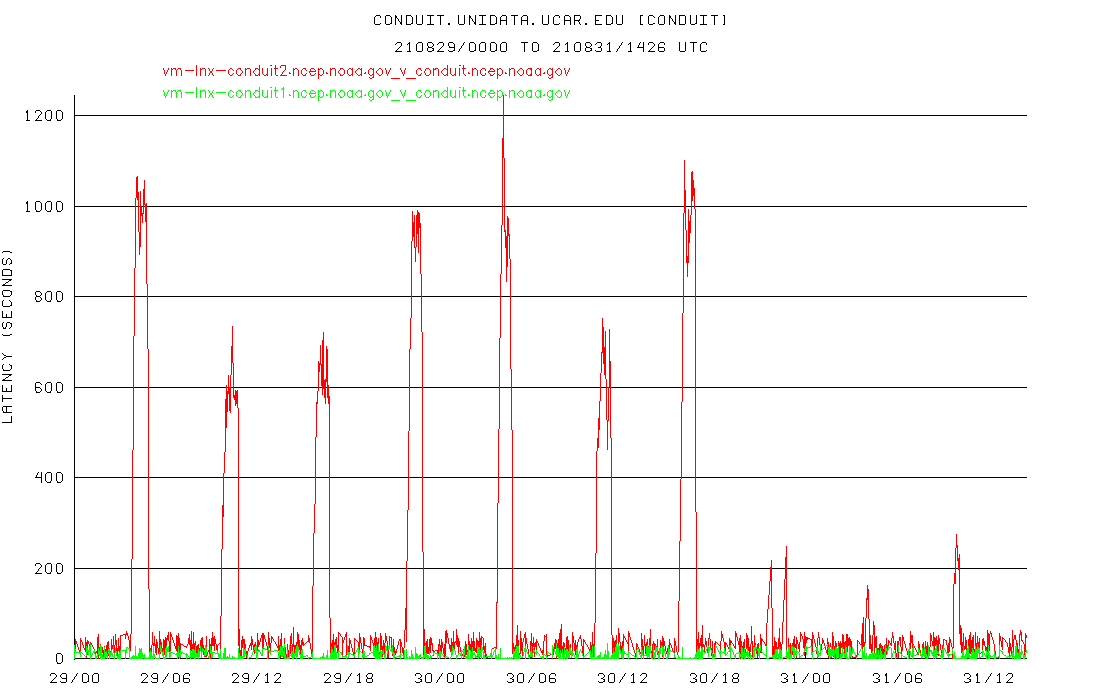
> Recently we have noticed fairly high latencies on the CONDUIT
> ldm data feed originating from the machine
> vm-lnx-conduit2.ncep.noaa.gov
> <http://vm-lnx-conduit2.ncep.noaa.gov>. The feed originating
> from vm-lnx-conduit1.ncep.noaa.gov
> <http://vm-lnx-conduit1.ncep.noaa.gov> does not have the high
> latencies. Unidata and other top level feeds are seeing similar
> high latencies from vm-lnx-conduit2.ncep.noaa.gov
> <http://vm-lnx-conduit2.ncep.noaa.gov>.
>
> Here are some graphs showing the latencies that I'm seeing:
>
> From
> https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/iddstats_nc?CONDUIT+idd-agg.aos.wisc.edu
> <https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/iddstats_nc?CONDUIT+idd-agg.aos.wisc.edu> -
> latencies for CONDUIT data arriving at our UW-Madison AOS ingest
> machine
>
>
>
> From
> https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/siteindex?conduit.unidata.ucar.edu
> <https://rtstats.unidata.ucar.edu/cgi-bin/rtstats/siteindex?conduit.unidata.ucar.edu> (latencies
> at Unidata)
>
>
>
> At least here at UW-Madison, these latencies are causing us to
> lose some data during the large GFS/GEFS periods.
>
> Any idea what might be causing this?
>
> Pete
>
>
>
>
> <http://www.weather.com/tv/shows/wx-geeks/video/the-incredible-shrinking-cold-pool>-----
> Pete Pokrandt - Systems Programmer
> UW-Madison Dept of Atmospheric and Oceanic Sciences
> 608-262-3086 - address@hidden <mailto:address@hidden>
>
>
>
> --
> Anne Myckow
> Dataflow Team Lead
> NWS/NCEP/NCO
>
>
>
> --
> Jesse Marks
> Dataflow Analyst
> NCEP Central Operations
> 678-896-9420
--
+----------------------------------------------------------------------+
* Tom Yoksas UCAR Unidata Program *
* (303) 497-8642 (last resort) P.O. Box 3000 *
* address@hidden Boulder, CO 80307 *
* Unidata WWW Service http://www.unidata.ucar.edu/ *
+----------------------------------------------------------------------+
--Jesse Marks
Dataflow Analyst
NCEP Central Operations
678-896-9420
--
Jesse MarksDataflow Analyst
NCEP Central Operations678-896-9420
--
Jesse MarksDataflow Analyst
NCEP Central Operations678-896-9420
--
Jesse MarksDataflow Analyst
NCEP Central Operations678-896-9420