This archive contains answers to questions sent to Unidata support through mid-2025. Note that the archive is no longer being updated. We provide the archive for reference; many of the answers presented here remain technically correct, even if somewhat outdated. For the most up-to-date information on the use of NSF Unidata software and data services, please consult the Software Documentation first.
|
Kevin,
Yes, we are seeing the large lags again, and losing data, I think because it ages out of our ldm product queue before we process it. Unidata folks, are your files also incomplete due to the large lags, or is that specific to us due to a too-small queue? I
am looking at the file sizes for the 0.25 deg runs on motherlode, and just looking at the file sizes, it appears Unidata also are missing data. Seems like a complete run should be ~47 Gb, and several are 41, 42, 39Gb..
GFS_Global_0p25deg_20210831_0000.grib2 2021-08-30 23:16 47G
GFS_Global_0p25deg_20210831_0600.grib2 2021-08-31 05:14 47G
GFS_Global_0p25deg_20210831_1200.grib2 2021-08-31 11:14 47G
GFS_Global_0p25deg_20210831_1800.grib2 2021-08-31 17:17 47G
GFS_Global_0p25deg_20210901_0000.grib2 2021-08-31 23:16 41G
GFS_Global_0p25deg_20210901_0600.grib2 2021-09-01 05:14 47G
GFS_Global_0p25deg_20210901_1200.grib2 2021-09-01 11:14 47G
GFS_Global_0p25deg_20210901_1800.grib2 2021-09-01 17:17 47G
GFS_Global_0p25deg_20210902_0000.grib2 2021-09-01 23:16 47G
GFS_Global_0p25deg_20210902_0600.grib2 2021-09-02 05:14 47G
GFS_Global_0p25deg_20210902_1200.grib2 2021-09-02 11:15 47G
GFS_Global_0p25deg_20210902_1800.grib2 2021-09-02 17:17 47G
GFS_Global_0p25deg_20210903_0000.grib2 2021-09-02 23:16 41G
GFS_Global_0p25deg_20210903_0600.grib2 2021-09-03 05:14 42G
GFS_Global_0p25deg_20210903_1200.grib2 2021-09-03 11:14 39G
If that is the case, that we are both dropping/losing data due to the lags, the maybe problem is that the product queues on the NCEP virtual machines are not large enough to handle the feed, does that seem correct?
My product queue on idd-agg is 78000 Mb (~78 Gb) - but that also handles other data such as the NEXRAD, NEXRAD2, HDS, etc.. however GOES16/17 data does NOT flow through that machine, so it doesn't contribute to the load there.
How big are the product queues on the Unidata CONDUIT ingest machines? Or on the NCEP source machines? Could a possible solution to this be to artificially delay the ingest of the GFS grids a bit to lower the peak amount of data going through? Maybe sleep
20 seconds or a minute or whatever between ingesting each forecast hour? I'd personally rather get a complete data set a bit later than an incomplete data set on time.
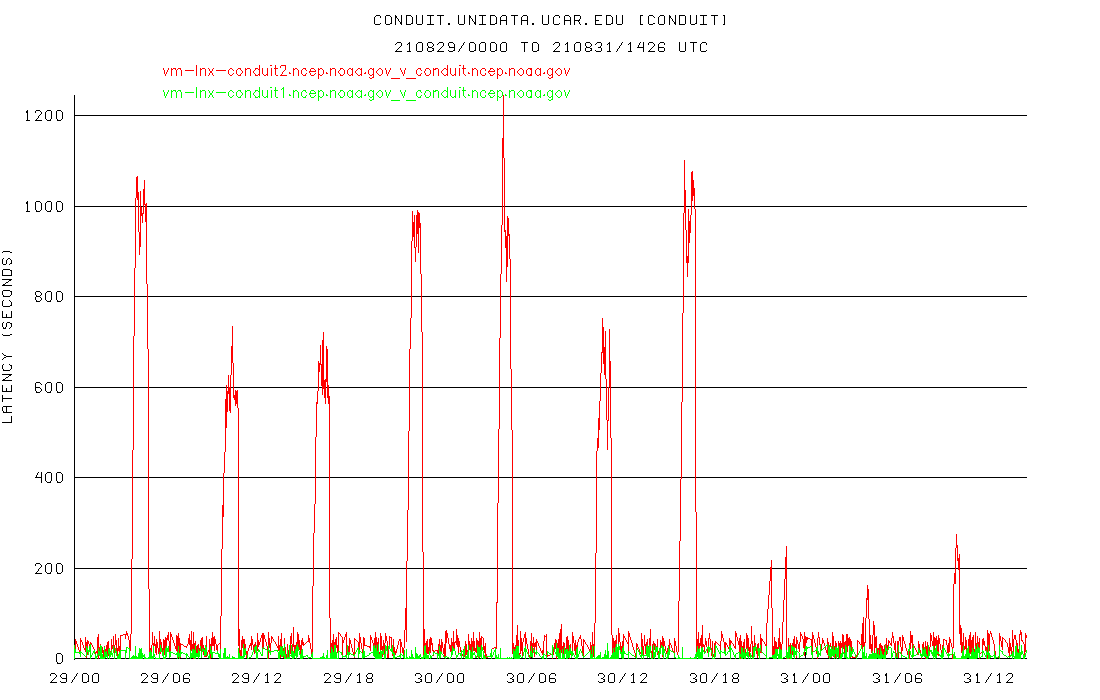
Here's the graph of lag from conduit.ncep.noaa.gov to idd-agg.aos.wisc.edu from the past two days. When lags get > 1000 seconds or so, that's the point where we and our downstreams start dropping/losing data..
It would really be helpful to get this resolved, whether it is a fix for whatever's causing the large lags at NCEP, or us acquiring an ingest machine with enough memory to handle a larger product queue (if the issue is us and not the upstream product queues
at NCEP), or something other than the CONDUIT data feed to distribute this data, or ?? It has come to the point where we can't rely on this data for plotting maps or doing analysis for classes, initializing local models, etc, because it has become so reliably
incomplete, for the GFS runs in particular.
Pete
 From: Tyle, Kevin R <address@hidden>
Sent: Friday, September 3, 2021 12:06 PM To: Pete Pokrandt <address@hidden>; Jesse Marks - NOAA Affiliate <address@hidden>; address@hidden <address@hidden> Cc: _NWS NCEP NCO Dataflow <address@hidden>; Anne Myckow - NOAA Federal <address@hidden>; address@hidden <address@hidden> Subject: RE: [conduit] 20210830: Re: High CONDUIT latencies from vm-lnx-conduit2.ncep.noaa.gov Hi all,
After a few good days, we are once again not receiving all GFS forecast hours, starting with today’s 0000 UTC cycle. Pete, do you note the usual pattern of increasing latency from NCEP?
Cheers,
Kevin
_________________________________________________
Kevin Tyle, M.S.; Manager of Departmental Computing
NSF XSEDE Campus Champion _________________________________________________
From: conduit <address@hidden> On Behalf Of Pete Pokrandt via conduit
Thanks for the update, Jesse. I can confirm that we are seeing smaller lags originating from conduit2, and since yesterday's 18 UTC run, I don't think we have missed any data here at UW-Madison.
Kevin Tyle, how's your reception been at Albany since the 18 UTC run yesterday?
-----
From: Jesse Marks - NOAA Affiliate <address@hidden>
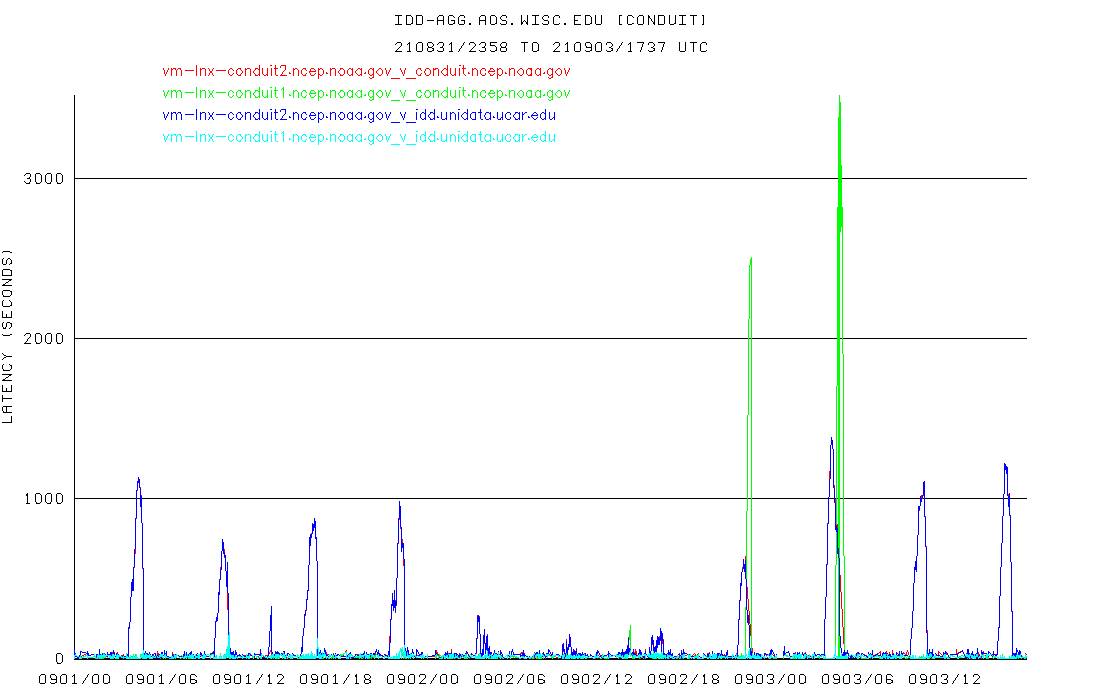
Thanks for the quick reply, Tom. Looking through our conduit2 logs, we began seeing sends of product from our conduit2 to conduit1 machine after we restarted the LDM server on conduit2 yesterday. It appears latencies improved fairly significantly at that time:
However we still do not see direct sends from conduit2 to external LDMs. Our server team is currently looking into the TCP service issue that appears to be causing this problem.
Thanks, Jesse
On Mon, Aug 30, 2021 at 7:49 PM Tom Yoksas <address@hidden> wrote:
Jesse Marks Dataflow Analyst NCEP Central Operations 678-896-9420 |